It can’t do everything, but it can a do a large number of useful things
It can do things more effectively with more information
It can use tools when it encounters scenarios that are solved sub optimally with token output eg: using code to do math instead of outputting a token that is probablistically next in a sequence.
as an AI engineer, I don’t want to have to write a new way to call tools for each new model api that comes out.
as a backend engineer, I don’t want to have to write a new service every time a new llm comes out to support its tool calling scheme.
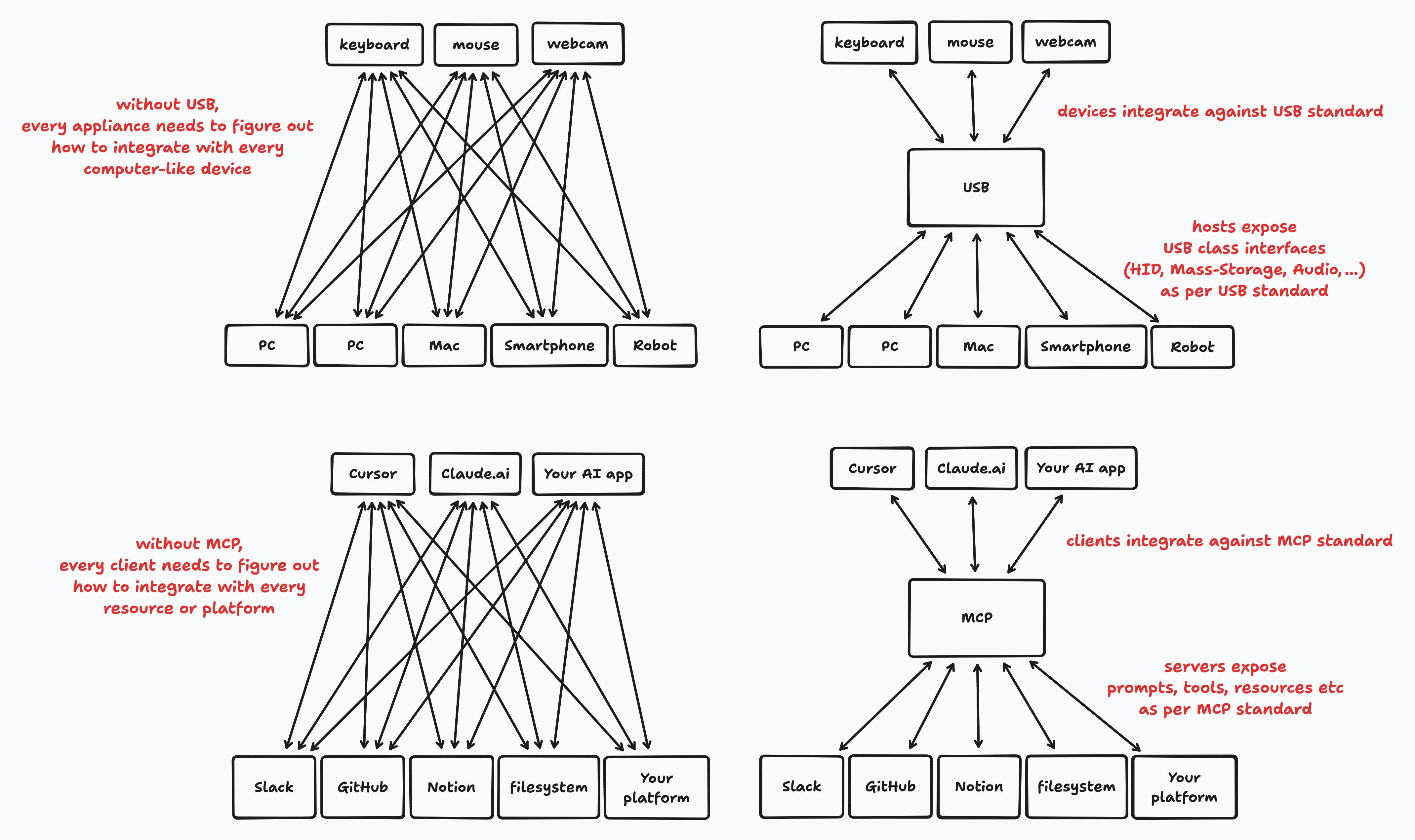
Lets standardize around a consensus on data transfer protocol between a llm and some data provider.
Turns M ⨯ N integration problem by turning it into an M + N integration problem.
Decouples AI client applications from AI tools and workflows for a platform.

from the offical python sdk readme
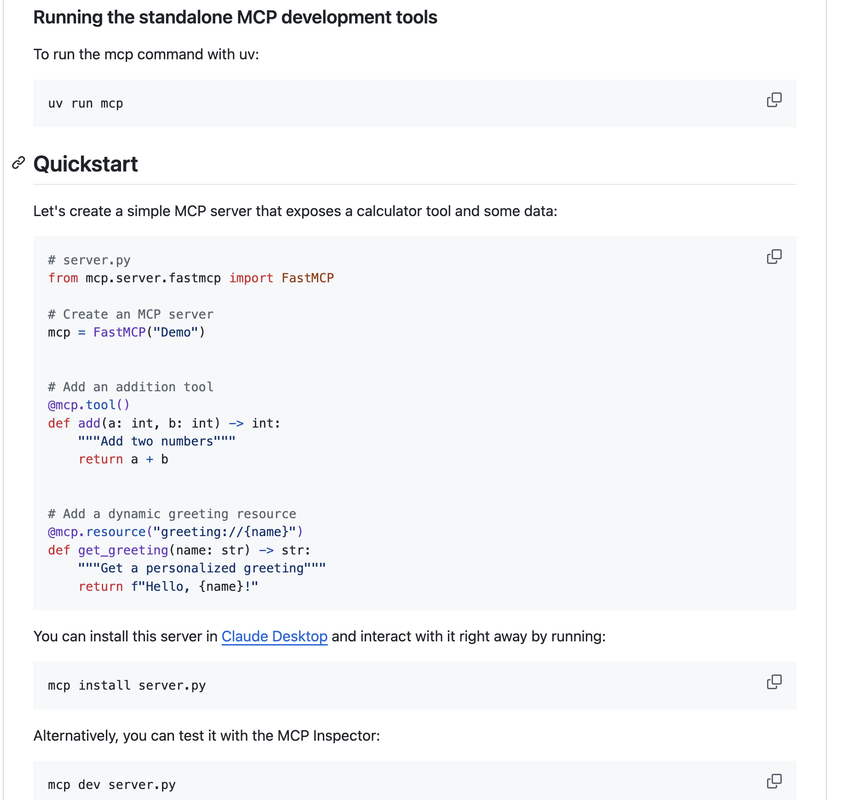
copied from my js code exections mcp server readme
Install the server as above.
Create or edit .cursor/mcp.json in your project root:
{
"mcpServers": {
"js": {
"command": "/usr/local/bin/mcp-v8",
"args": [
"--directory-path",
"/tmp/mcp-v8-heaps",
]
}
}
}
port forward if not already
ssh -L 6443:localhost:6443 saphira.flakery.xyz
whats are the resources on my cluster right now?
port forward neo4j
ssh -L 7687:localhost:7687 44.229.154.130
discussion on section schema and querying
Which led to this delightful query
MATCH (start:Section {clauseNumber: '10.6.4'}). // match section with clauseNumber 10.6.4
OPTIONAL MATCH (start)-[:PARENT_OF*]->(parent:Section) // recursively find its parents, if exists
OPTIONAL MATCH (start)-[:CHILD_OF*]->(child:Section) // recursively find its children, if exists
OPTIONAL MATCH path=(start)-[:LINKS_TO*1..2]->(linked:Section) // recursively find its linked sections, 2 layers deep
WITH COLLECT(DISTINCT parent) AS parents,
COLLECT(DISTINCT child) AS children,
COLLECT(DISTINCT linked) AS linkedNodes,
start // collect these all to distinct values, and include start
UNWIND parents + children + linkedNodes + [start] AS node // flatten into one list
WITH DISTINCT node WHERE node IS NOT NULL // filter to distinct values again
RETURN node // return the node
what is my current schema?

llms have limited context windows, and some data is too large to fit in that.
context is vast but pricey. prompting 51k tokens (1gb pdf file) costs $7.5k on google gen ai studio without even accouting for response tokens. They are also priced 4x more than input tokens.
llms clients interact with mcp as a context provider, but 2nd generation of mcp will be helping models manipulate data in storage providers and manipulate that data using its metadata (schema)
gen ui to interact with said data, without it flowing through the models context, to save on tokens.